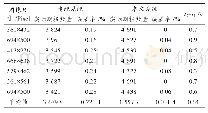
《表3 深度学习相似度匹配测试结果及与TF-IDF算法对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
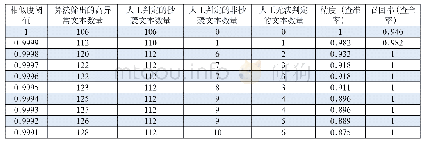
为验证基于深度学习的主题相关资源采集策略在信息监测系统中的应用效果。本文选择2017年12月至2018年10月监测系统通过主题爬虫从各开放知识资源获取网站采集的约3万条数据,筛选出4865条与海洋研究相关的新闻,对4865条数据进行人工标识之后,将训练集和测试集比例按照8:2进行划分,80%用于训练集,20%用于测试集。为准确评价主题相似度匹配的效果,本文选取的评价指标为准确率P、召回率R及F1-measure,F1-measure值为准确率和召回率的调和平均值。将机器检测结果与人工标记结果进行比对。传统计算文本相似度方法为基于向量空间模型的TF-IDF算法,该方法以词在文档中出现频率以及在文档集中出现该词的概率来表征词的权重。本文通过基于向量空间模型的TF-IDF算法与LDA和word2vec结合的算法进行了对比试验,对比实验用同样的文档集作为语料库,首先对语料库进行预处理,再利用TF-IDF算法把主题文档和测试文档表示成关于词项的向量,然后计算测试文档与主题文档的余弦相似度,根据相似度结果值设定合适阈值来作为监测结果,TF-IDF算法测试结果给出F1-measure值(监测结果见表3)。
| 图表编号 | XD0052167900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.04.25 |
| 作者 | 刘艳民、张旺强、祝忠明、陈宏东 |
| 绘制单位 | 兰州大学图书馆、中国科学院兰州文献情报中心、中国科学院兰州文献情报中心、兰州大学图书馆 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}