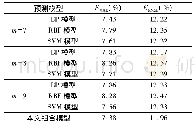
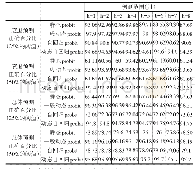
《表5 四种决策数模型的预测效果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
决策树类算法中最为常见的四种模型如下:决策树模型、随机森林模型、GBDT迭代决策树模型以及XGBoost模型。其中单一决策树模型是通过对已经有确切结果的历史数据进行分析获取其特征,然后以此为依据对新数据进行预测的方法,呈现树状结构。与其他模型相比,单一决策树模型更易于理解且效率较高,但是极易出现过度拟合问题。随机森林模型中包含多棵决策树,各决策树独立存在,通过投票确定预测结果,可有效缓解单一决策树的过度拟合问题。GBDT迭代决策树模型同样也是由多棵决策树构成,但其最终输出结果是由各个决策树结果相互累加形成。与上文所述模型相比,GBDT迭代决策树模型通过迭代可以有效拟合决策树的残差,降低样本损失,其训练效率更高,具有良好的建模和测试效果。而XGBoost模型是在GBDT迭代决策树模型基础之上进一步优化形成的,与GBDT迭代决策树模型相比,XGBoos t模型的优势得到进一步提升,具体表现在建模效果、训练效率、大规模并行化、二次收敛等方面[7]。本文分别以上述四种决策树算法为基础训练得到四种P2P借贷风险识别模型,并利用其对测试集中包含的4 000条借款记录分别进行预测,最终预测效果如表5所示。
| 图表编号 | XD0036729000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.20 |
| 作者 | 安英博、程冬玲 |
| 绘制单位 | 河北金融学院 |
| 更多格式 | 高清、无水印(增值服务) |

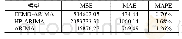


{kind=link}