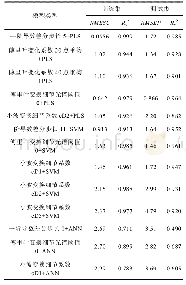
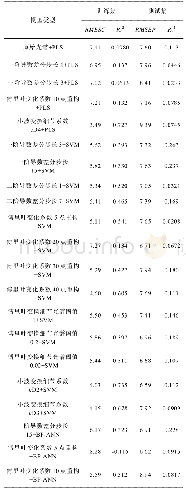
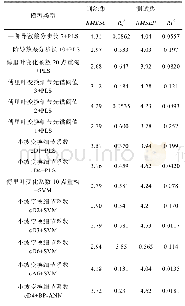
《表4 四种SVM模型预测效果对比情况》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
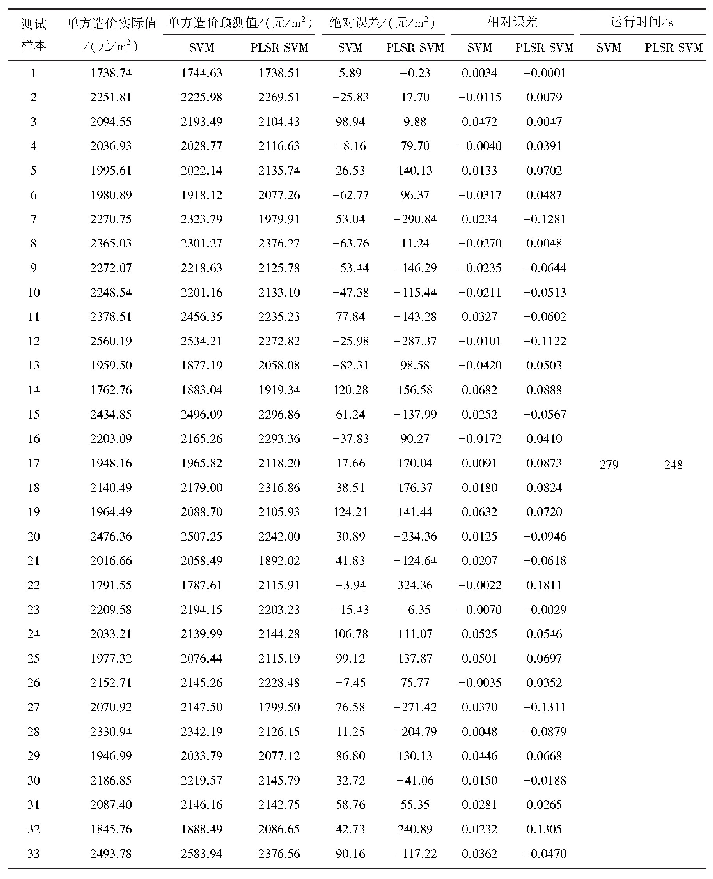
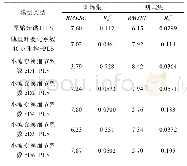
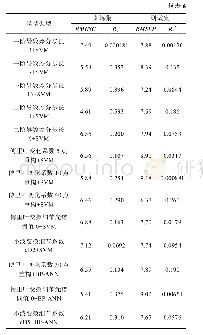
因为在字段维度与数据量较大的情况下,支持向量机模型训练的复杂度与时间会大幅度提高,所以为了减少模型训练的时间成本在模型训练之前采用了Ensemble SVM模型的方法,即通过对训练数据集实施多次抽样形成子训练集,针对每一个子训练集建立子模型然后利用子模型对测试样本进行预测,最后以投票方式获取最终预测结果。为了进行对比,本文还构建了Ensemble SVM模型以及涵盖所有训练数据的SVM模型。出于对P2P违约识别问题性质的考虑,又分别将Ens e mb le SVM模型与SVM模型划分为线性和非线性两类,其中非线性支持向量机模型以RBF径向基为基础。四种SVM模型预测效果的对比情况如表4所示。
| 图表编号 | XD0036729200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.20 |
| 作者 | 安英博、程冬玲 |
| 绘制单位 | 河北金融学院 |
| 更多格式 | 高清、无水印(增值服务) |
{kind=link}