《表3 不同聚类数在不同迭代次数下的召回率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
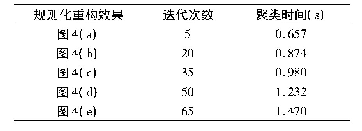
为了对RLPSO_KM_CF算法的推荐效率和推荐准确度进行分析,采取了以下几组实验:1) 对比RLPSO_KM_CF算法在不同聚类下的平均绝对误差值、召回率及F-Measure值,进而判断算法所选择的聚类参数值K;2) 对比RLPSO_KM_CF算法与传统基于用户的协同过滤推荐算法User-CF、基于聚类的协同过滤推荐算法KCF,进而判定本文算法的有效性;3) 对比RLPSO_KM_CF算法与其他改进推荐算法的平均绝对误差值,验证RLPSO_KM_CF算法的推荐准确度;4) 对比基于Spark的RLPSO_KM_CF算法与基于Hadoop的User-CF与Item-CF算法,验证算法的推荐效率.利用RLPSO_KM算法分别将用户划分成1~8个簇,同时,运用协同过滤推荐算法于每次迭代的每个簇类中,并且计算平均召回率和平均绝对误差值.表3为RLPSO_KM_CF算法在聚类数分别为1~8时得到的推荐结果的召回率.其中,聚类数为1时,RLPSO_KM_CF算法与传统的User-CF算法效果相当.
| 图表编号 | XD003480800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.12.01 |
| 作者 | 游思晴、周丽、赵东杰、薛菲 |
| 绘制单位 | 北京物资学院信息学院、北京物资学院信息学院、北京物资学院信息学院、北京物资学院信息学院 |
| 更多格式 | 高清、无水印(增值服务) |



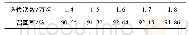

{kind=link}