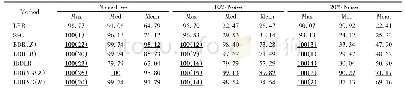
《表1 不同迭代次数下的聚类算法的时间 (h) 和准确率 (%)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
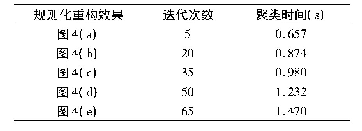
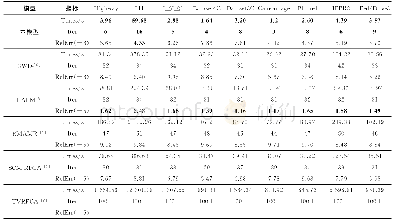
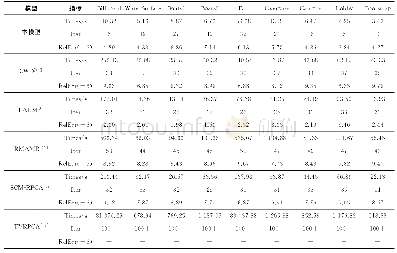
本次实验的软件环境是采用Hadoop和Mahout这两类软件工具,Hadoop是一种开源的机器学习分析工具,是能够基于Hadoop开展大量数据的挖掘分析,能够充分发挥集群数据的高速运算。通过收集基于江苏道路交通监控系统所采集到的实际数据,实验分别选取南通和常州2个城市所在的CZ1-NT2区间范围内的数据。在实验中,将PACO聚类算法与在同一场景中广泛使用的kmeans聚类算法进行了比较[4]。通过改变聚类算法放入迭代次数Gmax和领域的半径r以及阈值概率P的参数值进行实验。迭代的次数分别为10次、15次、20次,实验结果如表1所示。
| 图表编号 | XD0080206400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.25 |
| 作者 | 李明东、张万礼、卢彪、焦杰、陈小明 |
| 绘制单位 | 宿州学院信息工程学院、宿州学院信息工程学院、宿州学院信息工程学院、宿州学院信息工程学院、宿州学院信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}