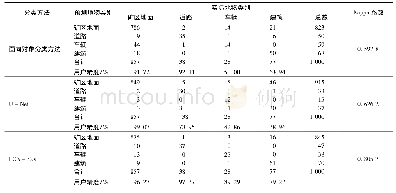
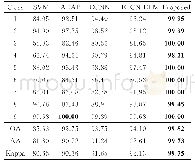
《表2 不同方法的分类结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在第一阶段试验中,固定50%的样本为有标签数据,其余的作为无标签数据,进行十折交叉验证。将有标签数据划分为10等份,在每次交叉验证中,将90%的有标签数据和所有无标签数据用于模型训练,剩余10%的有标签数据用于模型性能测试。试验重复10次,主要目的是避免样本的随机划分而导致结果偏差。比较试验结果与传统全监督模型的分类结果(见表2),可以看出,在所有数据上,所提方法的分类精度都要高于参与比较的其他方法,说明SLFS特征选择方法更能改进分类性能。
| 图表编号 | XD0029228000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.02.01 |
| 作者 | 吴锦华、万家山、伍祥、霍清华 |
| 绘制单位 | 安徽信息工程学院计算机与软件工程学院、安徽信息工程学院计算机与软件工程学院、安徽信息工程学院计算机与软件工程学院、安徽信息工程学院计算机与软件工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}