《表2 部分分词结果示例:基于BiLSTM-CRF的中医文言文文献分词模型研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于BiLSTM-CRF的中医文言文文献分词模型研究》
实验结果评价是将不同分词模型切分的结果与人工切分结果进行对比,使用测评常用的P(准确率)、R(召回率)和F1值作为评测指标[25]。其中,准确率P为模型正确切分出的词数与模型切分出总词数的比值,召回率R为系统正确切分出的词数与人工切分出的总词数的比值,F1值的计算公式为F1=2PR/(P+R)。表1展示了使用Bi LSTM-CRF模型进行中医文言文文献分词的部分结果;表2列出了不同模型在同一测试数据集上的部分分词结果;表3展示了使用不同模型在中医文言文文献上的分词结果。从表2可以看出,使用本文的Bi LSTM-CRF模型在中医文献上的分词结果的准确率、召回率和F1值高于Bi-LSTM模型,且远高于Ansj和jieba模型。从评价指标中可以发现目前中文主流通用领域的分词器如Ansj和jieba在特殊领域的应用效果是有局限性的,通过对分词结果的进一步分析对比发现,Ansj和jieba在对中医领域特有的术语名词分词时常常会作不应该的切分,这样就导致了结果的准确率和召回率都比较低;使用Bi-LSTM模型进行深度学习的方法能够较好地适用于中医领域的分词任务,比Ansj和jieba能提升约10%的准确率和召回率;而在Bi-LSTM模型上结合CRF模型达到了最优的效果,可以比单独使用Bi-LSTM模型提升约1%的准确率和召回率,能够满足分词下游任务的要求。
| 图表编号 | XD00222777700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.11.05 |
| 作者 | 王莉军、周越、桂婕、翟云 |
| 绘制单位 | 中国科学技术信息研究所、富媒体数字出版内容组织与知识服务重点实验室、北京科技大学、中国科学技术信息研究所、中央党校(国家行政学院)电子政务研究中心 |
| 更多格式 | 高清、无水印(增值服务) |
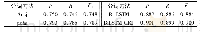





{kind=link}