《表1 基于机器学习和深度学习模型的古文自动分词研究汇总》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
部分学者[11-13]对比了基于规则的分词和基于统计的分词效果差异,实验结果均表明后者性能更优。采用CRF等传统机器学习模型和LSTM等深度学习模型,对不同历史时期的古文语料进行自动分词也是当前研究的主流方式。相关研究及模型算法性能,见表1。
| 图表编号 | XD00206690600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.01 |
| 作者 | 邓三鸿、胡昊天、王昊、王东波 |
| 绘制单位 | 南京大学信息管理学院、江苏省数据工程与知识服务重点实验室、南京大学信息管理学院、江苏省数据工程与知识服务重点实验室、南京大学信息管理学院、江苏省数据工程与知识服务重点实验室、江苏省数据工程与知识服务重点实验室、南京农业大学信息管理学院 |
| 更多格式 | 高清、无水印(增值服务) |
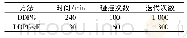





{kind=link}