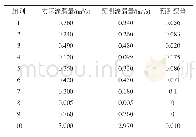
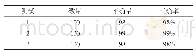
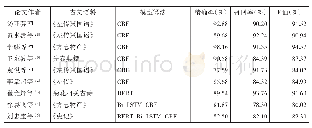
《表2 基于机器学习和深度学习模型的古文词性标注研究汇总》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
词性标注任务主要基于传统机器学习模型和深度学习模型开展。前者需要从语料中人工统计语言学特征来指导机器学习模型开展模型的训练与测试,而后者无需人工进行特征工程,神经网络会自动从文本中提取深层语言、语法、语义特征。相关研究及成果,见表2。
| 图表编号 | XD00206690700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.01 |
| 作者 | 邓三鸿、胡昊天、王昊、王东波 |
| 绘制单位 | 南京大学信息管理学院、江苏省数据工程与知识服务重点实验室、南京大学信息管理学院、江苏省数据工程与知识服务重点实验室、南京大学信息管理学院、江苏省数据工程与知识服务重点实验室、江苏省数据工程与知识服务重点实验室、南京农业大学信息管理学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}