《表4 深度学习模型与序列标注模型结果对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
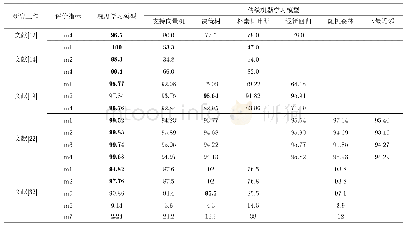
表4给出了基于序列标注模型和本文模型的对比结果,其中序列标注模型采用条件随机场模型,并使用了上文提到的各种子句特征。本文序列标注模型的实验结果和Gui等[15]实验结果有一定的差异,主要原因是本文采用了最新的新闻数据集,该数据集文本比微博语料更长,也更加复杂;另一方面,本文按照逗号分句,使非情绪原因子句所占比例大大增加,增加了情绪原因识别的难度,从而影响了实验的识别结果。从表4中可知,本文模型明显优于序列标注模型。虽然AM-BiLSTM方法准确率稍低,但召回率和F1值明显高于序列标注模型。该结果表明本文的方法在文本特征抽取方面更有优势。
| 图表编号 | XD0077700200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.24 |
| 作者 | 夏林旭、刘茂福、胡慧君 |
| 绘制单位 | 武汉科技大学计算机科学与技术学院、智能信息处理与实时工业系统湖北省重点实验室、武汉科技大学计算机科学与技术学院、智能信息处理与实时工业系统湖北省重点实验室、武汉科技大学计算机科学与技术学院、智能信息处理与实时工业系统湖北省重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}