《表4 算法参数表:基于深度学习的词汇表示模型对比研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
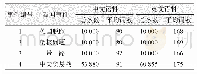
在基础实验中,将传统深度表示模型(Word2Vec、GloVe、FastText)和最新预训练模型(ELMo、BERT、XLNet)进行对比实验,比较不同词汇表示学习模型在多个文本分类任务上的具体表现;并探究传统深度表示模型分别利用TextCNN和Transformer在具体任务上进行特征抽取的效果。在参数设置过程中,尽可能保持6种模型在参数设置上的一致性;在由于模型结构差异导致无法取得一致的情况下,取参数的最优设置。传统深度表示模型Word2Vec、GloVe、FastText采用的词向量维度为100,词向量训练方式均使用最优的预训练词向量(更新)的方式,Word2Vec和FastText的训练方法均使用CBOW模型;最新的预训练模型中,BERT的多头注意力机制头数使用标准的12头,且加入位置嵌入信息,除此之外,所有模型的其余参数设置如表4所示。
| 图表编号 | XD00157147500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.25 |
| 作者 | 余传明、王曼怡、林虹君、朱星宇、黄婷婷、安璐 |
| 绘制单位 | 中南财经政法大学信息与安全工程学院、中南财经政法大学统计与数学学院、中南财经政法大学信息与安全工程学院、中南财经政法大学信息与安全工程学院、中南财经政法大学统计与数学学院、武汉大学信息管理学院 |
| 更多格式 | 高清、无水印(增值服务) |



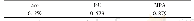

{kind=link}