《表3 中文分词相关的多任务联合模型文献分析》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
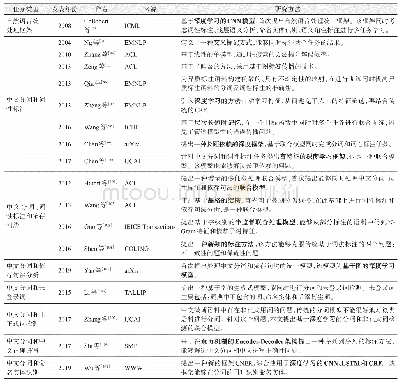
自然语言处理包括多个相关子任务。其中,与中文分词任务最紧密关联的任务是词性标注(Partof-Speech Tagging,POS Tagging)和依存句法分析(Dependency Parsing)。已有中文分词相关的多任务处理研究中,被研究最多的是中文分词和词性标注;其次为中文分词、词性标注和依存句法分析。除此之外,多任务还包括中文分词和依存句法分析;所有相关任务的自然语言处理统一框架;中文分词和未登录词识别;中文分词和非正式词检测;中文分词和中文正确拼写;中文分词和命名实体识别。筛选并统计分析重要的多任务联合模型研究,如表3所示。现有研究基本都是基于2004年Ng等[76]提出的交叉标记思想,再结合具体任务设计出一种统一的多任务标注方式,最后提出多任务联合的深度学习模型。融入依存句法和已有知识后,CNN和RNN都不能很好地解决这种具有网络结构的模型,图深度学习模型[74]开始被自然语言处理研究人员关注,未来如何结合和改进深度学习中的图深度学习模型[92]实现多任务学习,将成为重点研究方向。
| 图表编号 | XD00139940800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.25 |
| 作者 | 唐琳、郭崇慧、陈静锋 |
| 绘制单位 | 大连理工大学系统工程研究所、大连理工大学系统工程研究所、大连理工大学系统工程研究所 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}