《表1 中文分词部分词库对照表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
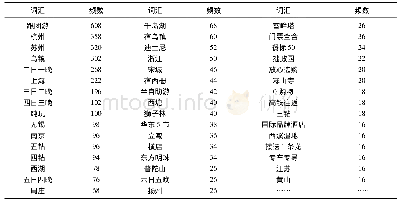
在数据挖掘方法的选择上,本文使用了支持向量机的监督分类方法。该方法建立在统计学习和经验风险最小的理论基础上,能够很好地解决小样本、非线性及高维模式识别方面的问题。利用支持向量机中核函数构建的超平面以区分不同行业的数据信息。在具体操作过程中,首先,从每个行业的数据中随机抽取10 000条以上的数据记录进行样本训练,统计各行业关键词出现的频率;然后,构建训练样本的特征空间分词库;最后,使用支持向量机的分类方法对未知文本进行筛选和分类。值得注意的是,对于中文网页文本的处理,使用中文分词方法[6]将文本区分为名词、动词、介词、连词、数词、标点符号、地名地址等(见表1)。
| 图表编号 | XD00115983200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.25 |
| 作者 | 姜代炜 |
| 绘制单位 | 广西基础地理信息中心 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}