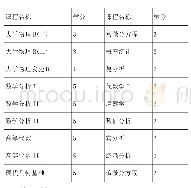
《表1 数据分词结果:基于招聘文本信息的信息与计算科学专业知识结构需求研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于招聘文本信息的信息与计算科学专业知识结构需求研究》
(1)jieba分词。对清洗好的数据转换为txt文本,用python开发的jieba库,它是优秀的中文分词第三方库。它有精确模式、全模式和搜索引擎模式三种分词模式。本文采用精确模式,即把文本进行精确切分,不存在冗余单词,适合文本分析。具体方法为:jieba.cut(s,cut_all=False)。s指需要分词的字符串;cut_all=False指采用精确模式,若为True即为全模式。将分词后数据另存。分词后如表1所示。
| 图表编号 | XD00164970100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.25 |
| 作者 | 袁旭、赵亚林、李滨全、万永庆、贾礼平 |
| 绘制单位 | 乐山师范学院数学与信息科学学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}