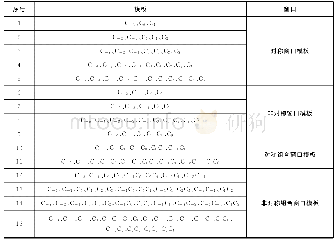
《表1 特征模板:基于BI-LSTM-CRF模型的维吾尔语分词研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于BI-LSTM-CRF模型的维吾尔语分词研究》
实验采用上下文单词设计的特征模板进行分词标注实验,单独训练上下文单词得到分词标注模型.本文实验采用的是Bigram模板,特征模板设定如表1所示.统计语料库中的词语长度,设定对称模板窗口长度最宽为5,共设计5组对称窗口模板实验,并根据维吾尔语的词语特点来设定非对称窗口模板和组合窗口模板,共15组特征模板.上下文单词描述符号设为char,在模板中的代号设为C.CRF模型实验结果如图4所示.
| 图表编号 | XD00121912400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.01 |
| 作者 | 孙雅婧、李成华、杨斌、江小平、艾提日也古丽·艾尼瓦尔 |
| 绘制单位 | 中南民族大学电子信息工程学院、中南民族大学电子信息工程学院、中南民族大学电子信息工程学院、中南民族大学电子信息工程学院、中南民族大学教育学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}