《表1 语料统计表:基于Bi-LSTM-CRF模型的维吾尔语词干提取的研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于Bi-LSTM-CRF模型的维吾尔语词干提取的研究》
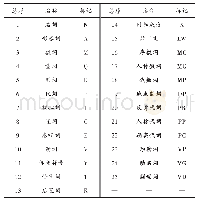
目前为止,由于维吾尔语词干提取公开的标注数据集或语料库还未见公开,因此本文将从天山网爬取新闻数据,并进行人工校对和人工提取词干(数据大小:15万),按词长进行由长到短的排序,并选出其中最长的1万个单词进行预处理,采用交叉验证法对标记语料进行分割产生训练集、测试集和验证集(分割比为0.75∶0.15∶0.1),语料具体统计如表1所示。
| 图表编号 | XD0070614200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.01 |
| 作者 | 古丽尼格尔·阿不都外力、吐尔根·依布拉音、卡哈尔江·阿比的热西提、王路路 |
| 绘制单位 | 新疆大学信息科学与工程学院、新疆大学新疆多语种信息技术实验室、新疆大学信息科学与工程学院、新疆大学新疆多语种信息技术实验室、新疆大学信息科学与工程学院、新疆大学新疆多语种信息技术实验室、新疆大学信息科学与工程学院、新疆大学新疆多语种信息技术实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}