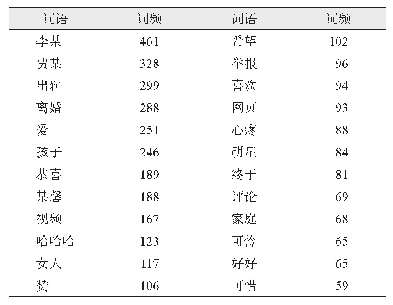
《表1 语料统计:基于表情符注意力机制的微博情感分析模型》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为了训练和测试语料,从新浪微博抽取了2017年4月份包含有表情符的10万条微博,使用jieba中文分词器进行分词,替换掉微博中的网址、用户及话题标签等。过滤掉长度小于5的微博文本。然后随机抽取其中的1万多条微博文本作为待标注微博,同时要求每个表情符出现的次数大于10次,去除重复以及表情符过少的微博后得到6 905条语料。在标注微博时,其情感标签分为正性、中性和负性三类。语料及标注统计如表1所示。
| 图表编号 | XD0067698400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.01 |
| 作者 | 谭皓、邓树文、钱涛、姬东鸿 |
| 绘制单位 | 武汉大学计算机学院、湖北科技学院计算机学院、湖北科技学院计算机学院、武汉大学计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}