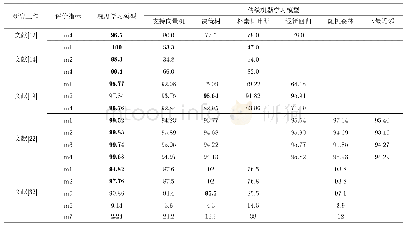
《表1 现有不良信息内容识别手段与深度学习的比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
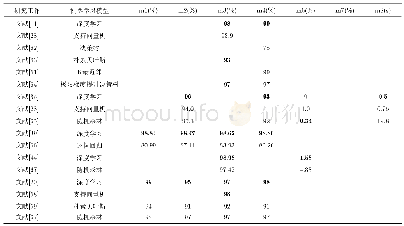
现有不良信息内容识别手段与深度学习技术的特性比较见表1。由表1可看出,相比现有不良信息内容识别手段,深度学习技术具有准确率高和泛化能力强的特点,和现有方法形成了很好的互补。另外,当模型确定时,模型使用的特征数量是固定可控的,不会随着训练数据的增加而增大。当然,深度学习模型也存在可配置性差的问题。由于模型提取特征的不可解释性,很难对模型的判别逻辑直接进行人工干预,修改模型的唯一可行方法是通过更新训练数据进行增量和全量训练。由于训练模型的过程比较耗时,所以模型更新一次的时间周期也比较长,不利于对新出现的不良信息进行快速的应对和识别。综上所述,深度学习技术与现有不良信息治理技术各有利弊,且能力互补。引入深度学习技术可以进一步加强不良信息内容识别能力,但并不意味其可以替代现有的治理手段。
| 图表编号 | XD00219905300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.11.15 |
| 作者 | 戴晶 |
| 绘制单位 | 中国移动通信集团公司信息安全管理与运行中心 |
| 更多格式 | 高清、无水印(增值服务) |



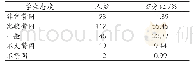
{kind=link}