《表4 在不同数据不同特征下现有基于深度学习的方法与基于传统机器学习的方法效果对比统计表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于深度学习的Android恶意软件检测:成果与挑战》
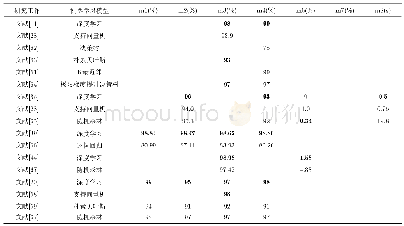
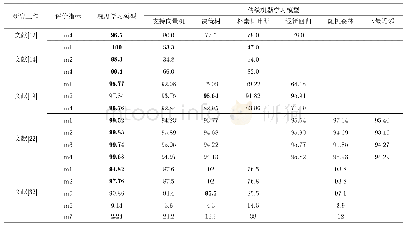
注:各评价指标的含义如下。m1:精确率(Precision),m2:召回率/真正率(recall/TPR),m3:F-measure,m4:准确率(accuracy),m6:假正率(FPR),m7:假负率(FNR),m8:检测时间
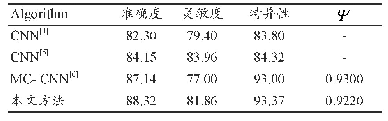
本文通过汇总分析现有工作所报告的检测效果发现,从总体上来说,相较于传统的机器学习模型,基于深度学习的Android恶意软件检测更为有效,其检测效果在各个评价指标上均有提升。同时,本文也发现了现有评测工作中存在的问题,主要有以下两点:(1)缺乏统一的测试集。由于缺乏统一的测试集,表4和表5中的研究工作所给出的比较结果有失客观性,无法准确衡量各个工作之间的优劣。故而,当前亟需一个统一的测试集供该领域的研究工作者在上面进行评测。文献[24,25]工作多年来持续收集、更新了千万数量级的Android应用并对他们进行标定,本文建议未来的的研究工作可以在这些开放数据集上进行评测。(2)缺乏标准的评价指标。本文从上述分析中还发现,评价机器学习模型效果的指标很繁杂,不同工作所使用的评价指标也各不相同。鉴于Android恶意软件检测可归纳为二分问题,即把一个Android应用分为良性软件或恶意软件,因此本文建议未来该领域的相关工作可采用机器学习二分工作通常采用的精确率(precision)、召回率(recall)以及F-measure这3个主要指标[70]进行模型评价。
| 图表编号 | XD00220299400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.01 |
| 作者 | 陈怡、唐迪、邹维 |
| 绘制单位 | 中国科学院信息工程研究所、中国科学院网络测评技术重点实验室、中国科学院大学网络空间安全学院、香港中文大学、中国科学院信息工程研究所、中国科学院网络测评技术重点实验室、中国科学院大学网络空间安全学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}