《表2 现有研究工作小结:基于机器学习的软件漏洞挖掘方法综述》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
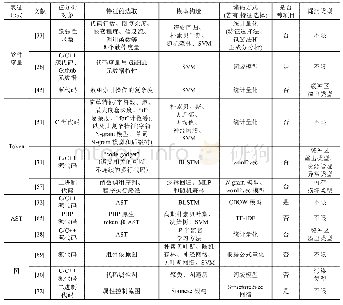
对于每种表征形式,本文从第2节梳理的研究工作中挑选了3项具有代表性的研究,按照技术特点进行总结.如表2所示,表中的每一行都代表一项研究工作.第1列代表了该项研究的代码表征形式.第3列为被分析对象的粒度,包括源代码、二进制代码以及函数块,其中,源代码又分别由C/C++、Java、PHP等编程语言编写.如果不指明编程语言的源代码,则表示该方法不限定编程语言.第4列为该项研究提取的特征,即依据表征形式从被分析对象中抽取哪些特征来表示源数据.第5列为该研究采用的机器学习方法,主要包括SVM、逻辑回归、朴素贝叶斯与BLSTM等.第6列为将代码表征转换成向量形式的方法,包括词袋模型、TF-IDF、统计量化以及word2vec等.如果有特征选择的过程,则第6列的括号内为特征选择所用的方法,包括基于相关性的特征选择法、包装法、主成分分析这3种方法.第7列代表该项研究是否实现跨项目,即是否能够通过有效迁移源项目的相关知识为目标项目构建预测模型[32].第8列代表该项研究的研究目标针对何种类型的漏洞,若该项为不限则表示该项研究的目标为构建通用漏洞检测模型,不局限于某种特定漏洞类型.
| 图表编号 | XD00168938400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.01 |
| 作者 | 李韵、黄辰林、王中锋、袁露、王晓川 |
| 绘制单位 | 国防科技大学计算机学院、国防科技大学计算机学院、中国人民解放军61302部队、国防科技大学计算机学院、国防科技大学计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}