《表4 性能表现:基于机器学习的SQL注入漏洞挖掘技术的分析与实现》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于机器学习的SQL注入漏洞挖掘技术的分析与实现》
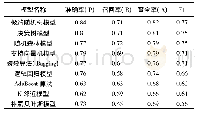
WALDEN[17]等人从71个版本的Moodle、95个版本的PHPMy Admin、30个版本的Drupal中一共整理出了223个漏洞,并通过手工分析、标记,将这223个漏洞制作成了用于机器学习的训练数据集,并将其公开(https://seam.cs.umd.edu/webvuldata/),此数据集中漏洞的具体分布情况如表3所示。然而,223个漏洞对于机器学习来说在数量上远远不够,更何况这223个漏洞还是分布在3个不同的开源Web应用程序中的不同类型的漏洞。虽然,WALDEN[17]等人将此数据集用于机器学习,并最终训练出基于软件度量的漏洞挖掘模型及基于文本分析的漏洞挖掘模型,但是这两个模型的表现均不尽人意,具体性能如表4所示。通过分析表3和表4可以发现,训练数据集中数据数量与训练出模型的性能成正比,当数据集所包含的数据量太小时,训练出模型的性能也比较差。
| 图表编号 | XD009438100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.10 |
| 作者 | 胡建伟、赵伟、闫峥、章芮 |
| 绘制单位 | 西安电子科技大学、西安电子科技大学、西安电子科技大学、西安电子科技大学 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}