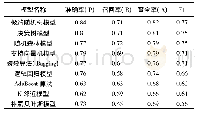
《表2 机器学习模型评价:基于机器学习的历史气候重建论文智能识别与数据挖掘初探》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
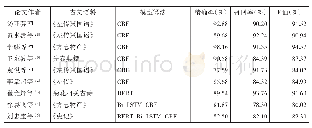
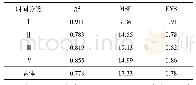
《基于机器学习的历史气候重建论文智能识别与数据挖掘初探》
但是,从ResearchGate数据集中分离出的两类文本的词频特征与上述NCDC范例数据的词频特征具有较为明显的差异。例如,在ResearchGate的重建文本中,“century”的频次极低,大幅低于NCDC中的频次,而“year”的频次较高,大幅高于NCDC中的频次;同样的,在ResearchGate的其他文本中,“change”的频次较低,大幅低于NCDC中的频次,而“glacial”、“water”的频次较高,大幅高于NCDC中的频次。形成这些差异的原因较为复杂,其中最主要的一个因素可能是样本量。NCDC的样本量是1000余篇,ResearchGate的样本量高达70余万篇。样本量增加意味着研究主题增加和作者数量增加,由此则导致文本表达的多样性更加丰富,一则表现为主题词多样性增加,二则表现为措辞类型更加多样。最终使得ResearchGate与NCDC同类型文本的词云图能够共同反映重建(研究)的基本特征,但是也呈现出较为明显的差异。
| 图表编号 | XD00192765800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.03.30 |
| 作者 | 华萌萌、尹君、胡召玲、张学珍 |
| 绘制单位 | 中国科学院地理科学与资源研究所中国科学院陆地表层格局与模拟重点实验室、江苏师范大学、中国科学院地理科学与资源研究所中国科学院陆地表层格局与模拟重点实验室、江苏师范大学、中国科学院地理科学与资源研究所中国科学院陆地表层格局与模拟重点实验室、中国科学院大学 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}