《表2 收入变量数据处理:基于机器学习的个人信用模型实证分析》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
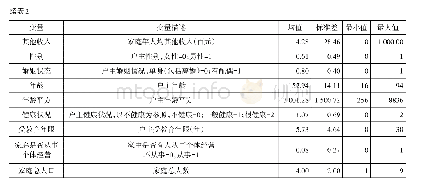
收入数据按照2017年个人所得税征税级距为梯度划分。收入数据虽然不存在“U型”数据难点,但是工资的额度增加不一定与信用评分呈线性关系,因此需要对工资进行再编码,使工资变换能够被分类器学习,并将收入映射到梯度区间。但是,由于其数值较大,可能会带来因数据单位不一致带来的参数变化,使得模型泛化能力较低,因此对其取以2为底的对数。一方面可以反映数据的变化趋势,另一方面可压缩数值,避免因为数据变化造成模型的效果差。与年龄不同的是,工资的每个阶段都有实质作用,因此需要记录每个阶段的数值,处理后部分结果如表2所示。
| 图表编号 | XD00172476000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.15 |
| 作者 | 张晖、张志明 |
| 绘制单位 | 铜陵学院金融学院、铜陵学院金融学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}