《表1 年龄变量数据处理:基于机器学习的个人信用模型实证分析》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
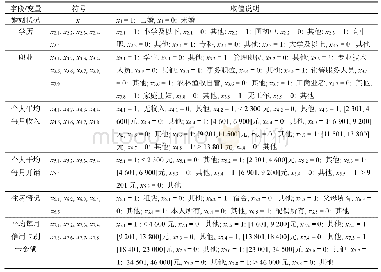
年龄变量是一个连续型变量,其数值对客户信用可能呈“U型”分布,即在年龄数值较小时或较大时对客户可信度具有负作用,中间数值呈正作用[9]。因此直接使用数据作为判断依据,可能对线性模型的评估带来障碍,需要对数据进行重新编码。针对年龄变量,以5岁为一个阶段划分区间,将年龄数据分为:(0,15]、(15,20]、(20,25]、(25,30]、(30,35]、(35,40]、(40,45]、(45,50]、(50,55]、(55,60]、(60,65]、(65,70],共12个区间。通过重新编码,将年龄1维数据转换成12维数据,让模型避免“U型”难点。经过重新编码后部分结果如表1所示。
| 图表编号 | XD00172475900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.15 |
| 作者 | 张晖、张志明 |
| 绘制单位 | 铜陵学院金融学院、铜陵学院金融学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}