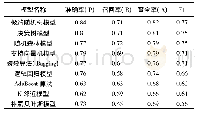
《表1 各机器学习模型的原理与优缺点》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于机器学习的历史气候重建论文智能识别与数据挖掘初探》
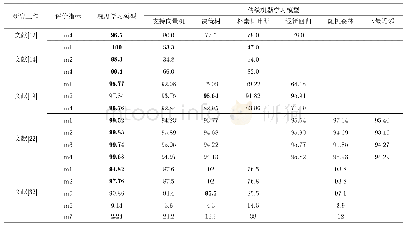
机器学习领域的文本分类模型多样,应用于不同类型的文本,其分类精度不一。本文利用NCDC数据集中经人工标注的范例文本(样本集),对9种常见的机器学习分类模型进行训练,包括:支持向量机模型[27]、决策树模型[28]、装袋算法[29]、随机森林模型[30]、逻辑回归模型[30]、极端随机树模型[31]、朴素贝叶斯模型[32]、K邻近值模型[33]和AdaBoost算法[34],各模型的原理不尽相同,并各有相应的优缺点(表1);然后,利用训练后的模型对NCDC中的其余文本(测试集)进行分类,并与人工标注结果进行比对,采用混淆矩阵方法评价了各模型精度,最后遴选出适用于历史气候变化重建论文摘要的最优分类模型。
| 图表编号 | XD00192765900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.03.30 |
| 作者 | 华萌萌、尹君、胡召玲、张学珍 |
| 绘制单位 | 中国科学院地理科学与资源研究所中国科学院陆地表层格局与模拟重点实验室、江苏师范大学、中国科学院地理科学与资源研究所中国科学院陆地表层格局与模拟重点实验室、江苏师范大学、中国科学院地理科学与资源研究所中国科学院陆地表层格局与模拟重点实验室、中国科学院大学 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}