《表1 语音识别测试表:基于深度学习的中文语音识别模型设计与实现》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
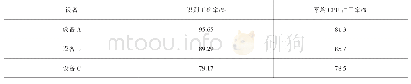
统计语言模型用于将拼音转换为最终文本以输出,本质被建模为隐含马尔可夫链,模型具有较高的精度。当传入的参数没有包含任何拼音时,返回为空。先取出一个字,即拼音列表中第一个字,依次从第一个字开始每次连续取两个字拼音,如果这个拼音在汉语拼音状态转移字典里的话,将第二个字的拼音加入,否则不加入,然后将现有的拼音序列进行解码,再重新从i+1开始作为第一个拼音。语音解码开始,如果这个拼音在汉语拼音字典里的话,获取拼音下属的字的列表,ls包含了该拼音对应的所有的字。在第一个字中,设置HMM的初始状态值,将初始概率设置为1.0,并将其添加到可能的句子列表中,否则,开始处理紧跟在第一个字后面的字。把现有的每一条短语取出来,尝试按照下一个音可能对应的全部的字进行组合,取出用于计算的最后两个字,判断它们是不是在状态转移表里,在当前概率上乘转移概率,公式化简后为第n-1和n个字出现的次数除以第n-1个字出现的次数,大于阈值之后保留,否则丢弃,最后对语言模型初始化。语音数据集采用ST-CMDS-20170001_1-OS等,对模型加以大数据训练后,抽取若干语音数据进行测试,平均准确率超过80%,效果较好,如表1所示。
| 图表编号 | XD00219611100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.01 |
| 作者 | 杨焕峥 |
| 绘制单位 | 江苏省无线传感系统应用工程技术开发中心、无锡商业职业技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}