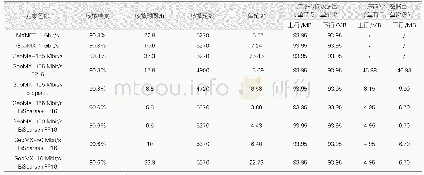
《表2 不同压缩方案与广域带宽下各维度优化效果对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
Geo MX:一种面向地理分布式机器学习的软件框架Bi Sparse:双向稀疏梯度传输FP:浮点数精度
为了验证上述优化技术应用于广域环境相比基础Geo MX应用于局域环境的增益,我们选择Geo MX-1 Gbit/s作为对比。表2数据表明,仅采用稀疏化技术就能取得约20%的训练效率增益(由10.6 h降到8.6 h)、10%的通信效率增益(由7.24 s降到6.58 s)以及90%的传输数据压缩率(上下行传输数据量分别由93.95 MB降到8.15 MB和9.90 MB),且保证收敛精度无损。对于两种优化技术相结合的方案,虽然稀疏梯度损失和半精度损失的双重影响导致了一定的收敛精度下降(由90.8%降到90.6%),但是对于对近50%的训练和通信效率增益(由10.6 h降到5.8 h、由7.24 s降到3.88 s)而言,损失0.2%的模型精度是可容忍的。为模拟带宽差异更显著的广域和局域通信环境,我们将广域带宽进一步限制到100/50/10 Mbit/s。由于广域带宽更加紧缺,每轮模型通信需要更长的时延,致使训练效率逐步劣化。在50 Mbit/s广域带宽下,Geo MX-Bi Sparse-FP16仍能取得趋同Geo MX-1 Gbit/s的训练效率(10 h vs.10.6 h)。当广域带宽持续减小时,即使近95%的传输数据压缩率也难以突破广域通信瓶颈,这就要求我们必须探索更先进的通信优化技术。
| 图表编号 | XD00218121100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.25 |
| 作者 | 李宗航、虞红芳、汪漪 |
| 绘制单位 | 电子科技大学、电子科技大学、鹏城实验室、南方科技大学、鹏城实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}