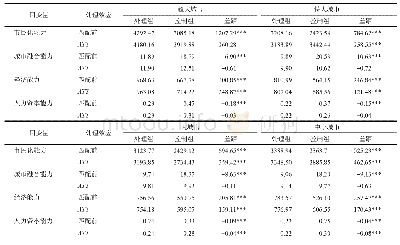
《表4 瘦身溢价倾向值匹配的平均处理效应(最近邻匹配)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《劳动力市场瘦身溢价的生成逻辑——人力资本与社会资本的综合解释》
注:其中ATT,ATU,ATE的标准误及Z值由bootstrap估计得到。T(Z)值在10%,5%,1%,0.1%显著性水平上显著的临界值分别为1.65,1.96,2.58,3.31。
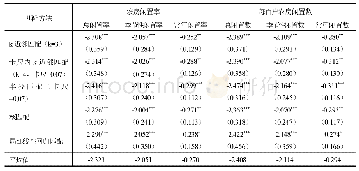
表5汇报了所有生成机制模型的拟合信息。从表5中可以看出,所有模型的卡方自由度比(χ2/df)都偏大一些,这可能与两个方面的因素有关。一是样本量较大,二是本研究的自变量、因变量和调节变量都是显变量,只有中介变量是潜变量,客观上容易使得模型的各项拟合指标不太理想,如卡方自由度比偏大,标准均方根残差(Standard Root Mean-square Residual,SRMR)的值偏大,但总体上可以接受。另外,近似误差均方根(Root Mean Square Error of Approxima‐tion,RMSEA)大多小于0.08,比较拟合指数(Comparative Fit Index,CFI)和塔克—刘易斯指数(TuckerLewis Index,TLI)也大多大于0.9,说明整体上各个模型的拟合效果较好。
| 图表编号 | XD00210588100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.01 |
| 作者 | 杨育土、丘海雄 |
| 绘制单位 | 中山大学社会学与人类学学院、中山大学社会学与人类学学院 |
| 更多格式 | 高清、无水印(增值服务) |
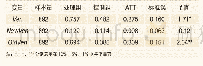

{kind=link}