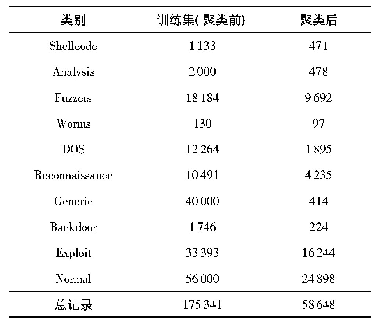
《表3 试验数据集的样本构成》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
首先,通过在建立的数据集中选取30 826道公路雷达A-scan数据,将这些数据按照7:3的比例划分为训练样本和测试样本。为了消除因为各类别数据的比例差异过大对算法的识别结果造成较大影响,对两类高速的正常类病害数据进行充分混合和扩充,试验数据集比例约为1.3:1.5:1.3:1,使得样本比例较为均衡,如表3所示。
| 图表编号 | XD00209373300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.01 |
| 作者 | 杜豫川、都州扬、刘成龙 |
| 绘制单位 | 同济大学道路与交通工程教育部重点实验室、同济大学道路与交通工程教育部重点实验室、同济大学道路与交通工程教育部重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}