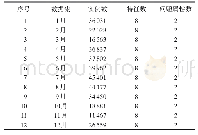
《表1 所选用数据集的样本数和特征数》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
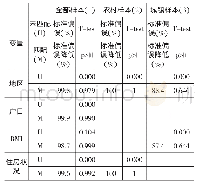
借鉴文献[22]的实验方案和数据集使用,采用10组UCI公共数据集进行实验,其中diabetes、credit-g、kr-vs-kp样本数量规模较大,10个数据集的样本个数和特征个数如表1所示。实验中操作系统为Windows7,CPU为Intel Core i5-3230主频2.60 GHz,内存为8 GB,编程语言为Python3.6。采用5×10重交叉验证和分层抽样的方法将数据集划分成5份,每次选取1份作为测试集,其余作为训练集,循环10次,计算10次精度均值作为模型最终精度结果。算法的运行时间为算法达到最优精度所消耗的时间。
| 图表编号 | XD00119666600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.01 |
| 作者 | 邵良杉、李臣浩 |
| 绘制单位 | 辽宁工程技术大学软件学院、辽宁工程技术大学软件学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}