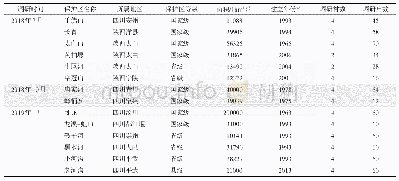
《表1 样本数据来源及选用口径情况一览》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《大数据在“穿透式”识别金融风险中的应用研究——基于k-means聚类方法的中小银行同业业务风险识别》
由于建立的三项映射指标:银行贷款占总资产比例(A)、贷款利息收入占总利息收入比例(I)、贷款损失准备占各项减值准备比例(P)均为分项与总项比例,量纲一致,不需要对各变量进行归一化处理。通过运用MAT-LAB分析软件对样本数据按照k-means算法进行聚类,在具体聚类操作中,在分类数(k值)选取上,本文采用轮廓系数法(Silhouette Coefficient),通过令k值从2向上递增的方式进行枚举,计算当前k的平均轮廓系数,同时在每个k值上多次重复运行k-means聚类以避免局部最优解问题,最后选取与轮廓系数最大的值相对应的k值作为最终的集群数目。当k值从“2”逐步增加到“5”时轮廓系数如表2所示,最终选取k值为3作为聚类标准。
| 图表编号 | XD0017918100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.07.25 |
| 作者 | 陈羲 |
| 绘制单位 | 中国人民银行贵阳中心支行 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}