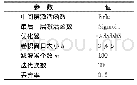
《表4 相关参数设置:基于伪标注样本融合的领域分词方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
作为对比,使用文献[6]的Bi LSTM模型与文献[10]的Bi LSTM-CRF模型以及jieba分词与本文的Bi-GRU+Conv1D-CRF模型进行对比。训练时使用Early-Stopping预防过拟合,使用学习率衰减避免在训练后期学习率过大。3个模型的超参数基本一致,最终的实验参数见表4。
| 图表编号 | XD00207697500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.20 |
| 作者 | 胡潇涛、吴浩、杨亮、顾小平、宋弘 |
| 绘制单位 | 四川轻化工大学自动化与信息工程学院、四川轻化工大学自动化与信息工程学院、人工智能四川省重点实验室、四川轻化工大学自动化与信息工程学院、四川轻化工大学自动化与信息工程学院、四川轻化工大学自动化与信息工程学院、人工智能四川省重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}