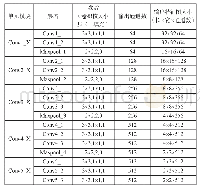
《表2 各类字位标注集:无池化层卷积神经网络的中文分词方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
之后,文献[2]使用最大熵(Maximum Entropy,ME)Markov模型第一次将序列标注学习方法应用到分词任务中,表2显示不同的序列标注集。文献[3]和文献[4]又将标准的序列标注学习方法——条件随机场(Conditional Random Field,CRF)引入到分词学习任务当中。自此以后,CRF的各种变种方法便成为主流的非深度学习分词模型,这些模型构成了传统的分词方法。然而,传统的分词方法的表现十分依赖于人工处理的特征。
| 图表编号 | XD00119681500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.15 |
| 作者 | 涂文博、袁贞明、俞凯 |
| 绘制单位 | 杭州师范大学信息工程学院、移动健康管理系统教育部工程研究中心、杭州师范大学信息工程学院、移动健康管理系统教育部工程研究中心、杭州师范大学信息工程学院、移动健康管理系统教育部工程研究中心 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}