《表2 模型超参数:融合词结构特征的多任务老挝语词性标注方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
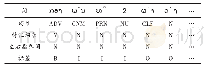
实验使用的老挝语语料有两部分:第一部分是词性标注语料(2 142个句子),该语料是把老挝文本先分词,然后标注词性(28种);第二部分是额外准备的分词语料,有1 068个句子。语料取自老挝网站,并且经过人工分词及标注。实验将词性标注语料库的85%作为训练集(1 822个句子),15%作为测试集(320个句子)。训练集和测试集分别用来训练和测试本文提出的词性标注模型,而训练集的分词及第二部分的分词语料用于训练词向量矩阵、字符向量矩阵及相似度计算模型。模型实现使用Python语言及Tensorflow框架。词性标注模型经过多次实验调整后,超参数设置如表2所示。
| 图表编号 | XD00109142600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.01 |
| 作者 | 王兴金、周兰江、张建安、周枫 |
| 绘制单位 | 昆明理工大学信息工程与自动化学院、昆明理工大学信息工程与自动化学院、昆明理工大学信息工程与自动化学院、昆明理工大学信息工程与自动化学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}