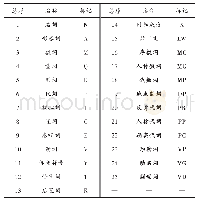
《表1 2个模型的中文词性标注的实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
%
本实验采用Python语言编程实现基于MEM和HMM的中文词性标注算法,并在Inter(R)Core(TM)[email protected]、4G内存、Win10操作系统条件下进行实验.采用北京大学加工整理的《人民日报》1998年1月份的新闻语料作为训练集和测试集.为了测试2个模型的实际标注效果,从训练的语料库中随机选取1 000行语料作为测试样本1,随机选取2 000行语料作为测试样本2.2个模型的词性标注准确率、召回率和F1这3个性能指标的比较见表1.
| 图表编号 | XD00150146400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.25 |
| 作者 | 周潭、莫礼平、胡美琪、李航程 |
| 绘制单位 | 吉首大学信息科学与工程学院、吉首大学信息科学与工程学院、吉首大学信息科学与工程学院、吉首大学信息科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}