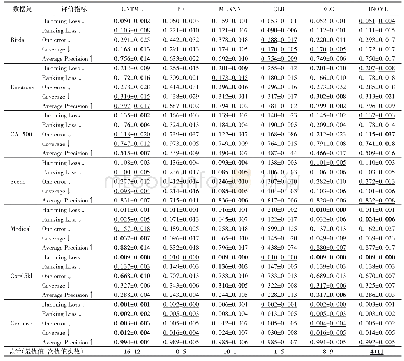
《表2 多标记学习算法的对比实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文实验中随机从数据集中选出2/3作为训练集,剩下1/3作为测试集,由于实验存在随机性,本文实验重复运行30次,求得最后的平均值和标准差。本文所提模型与其他对比模型的实验结果如表2所示,由于每个数据集都是随机划分的,因此表中每个评价指标给出最后结果的平均值和标准差,并将最优值标记为粗体,次优值标记为下划线,最后一行统计了各个算法分别取得最优值和次优值的次数。从表中可以观察到,本文提出的模型GNTML在7个真实数据集的5个评价指标上,66.7%(28/42)情况下取得最优值或次优值,其中38.1%(16/42)的情况下取得最优值,28.6%(12/42)的情况下取得次优值,相比于其他算法有一定的优势。作为多标记学习的经典基本算法BR,由于没有考虑标记之间的关联关系,所以它的结果是很一般的,最优值情况为0%,次优值仅占11.9%。ECC算法通过集成学习结合基方法,由于要将上一个预测的标记结果输入到下一个预测数据集中,所以考虑到了标记关联,因此性能要比BR有了很大的提升,在19.0%情况取得最优值,21.4%取得次优值。ML-k NN算法虽然在Scene数据集上能表现出优异性能,但是在其他数据集上表现却是一般,因此不是很稳定。HONML模型算法也稍弱于GNTML。
| 图表编号 | XD00201757000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.10 |
| 作者 | 林腾涛、查思明、陈蕾、龙显忠 |
| 绘制单位 | 南京邮电大学计算机学院软件学院网络安全学院、南京邮电大学计算机学院软件学院网络安全学院、南京邮电大学计算机学院软件学院网络安全学院、江苏省大数据安全与智能处理重点实验室(南京邮电大学)、南京邮电大学计算机学院软件学院网络安全学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}