《表1 实验数据集:基于GBDT的标记分布学习算法研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
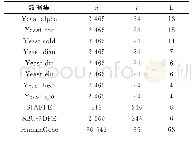
本文实验总共采用了12组数据集,其中Yeast的9种数据集都是酿酒酵母的数据集,每组有2 465个酵母菌基因样本,每个样本有24个特征,记录各个时间点的酵母菌基因表达水平为标记分布。s-JAFFE和s-BU_3DFE是有243个特征的人类表情数据集,以6种表情作标记,不同人对照片以6种表情作评分处理,然后以评分结果得出标记分布数据。Movie是7 755部电影的评分数据,1 869个特征,5种电影级别作为标记,以该级别人数占总人数比例得出标记分布。具体数据集如表1所示。
| 图表编号 | XD00144912100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.15 |
| 作者 | 王远志、陆文成、田文泉、高标 |
| 绘制单位 | 安庆师范大学计算机与信息学院、安庆师范大学计算机与信息学院、安庆师范大学计算机与信息学院、安庆师范大学计算机与信息学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}