《表1 数据描述性统计:样本稀疏表达的标记分布学习算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
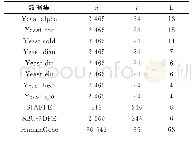
本文实验所用的11个数据集中,前8个来自于一组啤酒酵母生长生物实验中的真实数据,其中每个数据集都是一次真实实验的结果。此组数据集原有10个,由于本文主要研究借助标记相关性训练标记分布模型,所以去除了标记分布中标记数小于3的缺少标记间相关性的数据集。每个酵母基因数据集中包含2 465个基因实例,每个基因由一个长度为24的关联动植物轮廓向量描述,标记由生物实验中的离散时间点组成,用不同时间点的基因表达水平(已经过标准化)表示标记对实例的描述程度。SJAFFE、SBU-3DFE这两个数据集由应用十分广泛的面部表情图像数据集JAFFE、BU_3DFE改造而来,均为标记分布数据集。SJAFFE、SBU-3DFE数据集的每幅图像都由6个基本表情构成的标记分布表示,每个表情对某张图像的描述度是60个志愿者1~5打分后标准化的平均值。HumanGene数据集是一个包含30 542个样本的大规模数据集,它来自于研究人类基因与疾病之间关系的真实生物实验数据,其标签空间由68种不同疾病组成。数据集的详细数据统计信息如表1所示。
| 图表编号 | XD00210423800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.11.10 |
| 作者 | 邵佳鑫、原盛、刘新媛、刘睿馨 |
| 绘制单位 | 西安交通大学软件学院、西安交通大学软件学院、西安交通大学软件学院、西安交通大学软件学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}