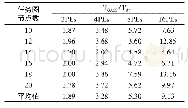
《表3 全连接拓扑结构(CCR=0.1)时2种算法的加速比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本节通过在不同数量的PEs上运行本文提出的OAPS算法和A*算法,观察2种算法的加速比,从而来评价OAPS算法的加速性能.表3所示为对于4个处理器在完全连接拓扑和CCR为0.1时得到的加速比结果.表的第二、第三、第四和第五列分别对应于2、4、8和16个Paragon PE情况下的加速比,最后一行为所考虑的全部任务图的平均加速比.从表3可见,在不同PEs数目的情况下,对于全部任务图来说,OAPS算法与A*算法的加速比始终大于1,说明OAPS算法具有比A*算法更好的加速性;而且在相同PEs的情况下,加速比几乎是呈线性的,随着PEs数目的增加而增大,说明本文提出的OAPS算法是稳定可靠的,同时有很好的扩展性.
| 图表编号 | XD00200592500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.01 |
| 作者 | 高卫斌、柳晓龙 |
| 绘制单位 | 宁德职业技术学院信息技术与工程系、福建农林大学计算机与信息学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}