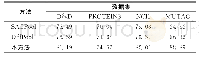
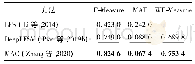
《表2 不同方法的数据集检测准确率对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
%
实验采用了SAGPool[11]和DiffPool[5]模型作为对比,在4个数据集上的检测准确率如表2所示。从表2可看出,本方法的分类精度明显优于对比模型。结合表1可得,本方法使用的数据集越大,其效果提升越明显。这是因为在层内特提取模块中应用了池化层,每经过一次池化操作,不可避免地会损失一些信息,大数据集在经过池化操作后,仍能保留大部分特征信息,而小数据集可能因为损失了大部分信息,导致剩余的特征信息不足以保证自身表达的完整性。
| 图表编号 | XD00190343700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.25 |
| 作者 | 张红梅、李浩然、张向利 |
| 绘制单位 | 桂林电子科技大学信息与通信学院、桂林电子科技大学广西高校云计算与复杂系统重点实验室、桂林电子科技大学信息与通信学院、桂林电子科技大学信息与通信学院、桂林电子科技大学广西高校云计算与复杂系统重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}