《表2 不同k值对应的先验框宽高》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
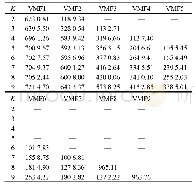
由图6可以看到,随着先验框数目不断增多,两种算法的平均交并比都在不断增大,但K-means++算法的准确度更高,曲线更为平滑,趋势更为稳定,可在一定程度上减小聚类偏差。由表2可以看到,先验框的数目k值超过9时会出现大小较为相近的聚类结果,产生数据冗余。增加先验框的数量会导致模型的检测速度变慢,但综合考虑检测的准确性,实验最终选择K-means++算法聚类生成的9个先验框,具体的参数为(60,59),(75,105),(100,147),(136,81),(146,205),(192,293),(210,133),(278,385)和(280,218)。
| 图表编号 | XD00162234300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.25 |
| 作者 | 吉训生、滕彬 |
| 绘制单位 | 江南大学物联网工程学院、江南大学物联网工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}