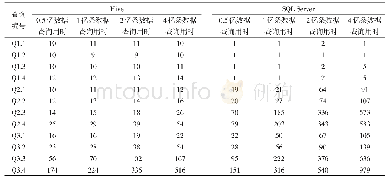
《表3 Hive和SQL Server在不同数据集上的查询时间》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
s
12条查询在Hive和SQL Server上的不同的数据集上执行时间如表3所示。由表3可以看出第1类查询(Q1.1至Q1.4)在SQL Server上的执行时间极短约为1~2 s,而在Hive上的执行时间却有10 s左右。究其原因,是因为这一类查询在查询条件中限定了地区和站点,由于在SQL Server上建立分区视图是使用Check约束限定了每张数据表的站点编号,在SQL Server上执行这一类查询时查询分析器只需找到所查站点的数据表并将其读入内存进行计算即可。而在Hive上执行,首先Spark集群有额外的建立线程、分配内存及销毁现场等操作,然后Hive需按照分区的层次,读入计算所需要的数据文件到内存后,才能进行计算。这些集群环境的额外时间开销使得基于Hive的方法在执行限定了具体站点的查询时耗时长。
| 图表编号 | XD00156451800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.01 |
| 作者 | 彭贝、刘黎志、杨敏、张晨跃 |
| 绘制单位 | 智能机器人湖北省重点实验室(武汉工程大学)、武汉工程大学计算机科学与工程学院、智能机器人湖北省重点实验室(武汉工程大学)、武汉工程大学计算机科学与工程学院、智能机器人湖北省重点实验室(武汉工程大学)、武汉工程大学计算机科学与工程学院、智能机器人湖北省重点实验室(武汉工程大学)、武汉工程大学计算机科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}