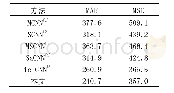
《表3 各近邻检索方法在数据集ANN_SIFT1M上的查询准确率与查询时间对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
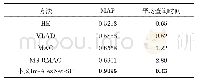
如表2和表3所示,乘积量化树[17]案例PQT0的配置为k1=64,k2=8,P=2,w1=8,即该树形结构第一层运用乘积量化,组别数目为2,每组划分成64个子空间,剪枝参数为8,每个子空间在第二层中运用向量量化细分,码本大小为8.选取前500个最近邻簇参与重排序即M=500,并从这些候选向量中由近至远选不超过20 000个向量参与重排序与查询向量比对,即LC的大小小于等于20 000.簇内乘积量化结构案例C-PQT0的参数配置为k1=4,k2=32,P=2,k3=8,w1=2,w2=16,近邻簇筛选出的大小为M=500,LC的大小小于等于20 000;C-PQT1的配置同C-PQT0,但最近邻簇筛选出的大小为M=1000;C-PQT2的配置为k1=8,k2=32,P=2,k3=1,w1=1,w2=4,近邻簇大小和LC的大小同C-PQT0.从表2和表3得出,本文提出的簇内乘积量化树技术在Sift算子描述的数据集上获得了优越的近邻检索性能,与前人提出的经典算法相比,相同查询时间内可获得更高的查询准确率.其中首次召回准确率R@1相比乘积量化树技术提高了57.7%,同局部优化乘积量化技术相比,查全率也可高达97%,查询时间却仅需其1/9.
| 图表编号 | XD00134458200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.01 |
| 作者 | 刘淑伟、陈威、赵伟、陈进才、卢萍 |
| 绘制单位 | 华中科技大学武汉光电国家研究中心、华中科技大学信息存储系统教育部重点实验室、华中科技大学武汉光电国家研究中心、华中科技大学信息存储系统教育部重点实验室、华中科技大学计算机科学与技术学院、华中科技大学武汉光电国家研究中心、华中科技大学信息存储系统教育部重点实验室、华中科技大学信息存储系统教育部重点实验室、华中科技大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}