《表1 基于强化学习的功率与信道联合干扰算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
策略学习更新阶段:干扰机通过当前时隙获得的奖励值更新Q值表,并且根据更新后的Q值表通过玻尔兹曼更新策略决策出下一时隙的干扰信道。干扰机在之后每一个时隙都经历相同的决策过程,并不断更新Q值表。通过不断训练Q值表强化对环境的认知,最终在复杂动态变化的环境下干扰机可以决策出最佳干扰策略。本文提出的信道与功率联合干扰决策算法如表1所示。
| 图表编号 | XD00156311800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.10 |
| 作者 | 张双义、沈箬怡、陈学强、田华、张潇、杜吉庆 |
| 绘制单位 | 中国人民解放军陆军工程大学通信工程学院、中国电子科技集团公司第二十八研究所、中国人民解放军陆军工程大学通信工程学院、中国人民解放军陆军工程大学通信工程学院、中国人民解放军陆军工程大学通信工程学院、中国人民解放军32753部队 |
| 更多格式 | 高清、无水印(增值服务) |
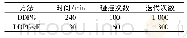




{kind=link}