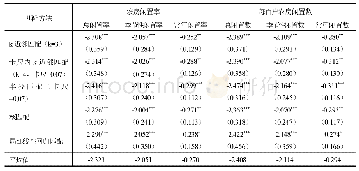
《表5 全样本及分样本倾向得分匹配的ATT处理效应》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《非正规就业对居民工作满意度的影响——来自中国劳动力动态调查数据的经验分析》
注:1.此处以0.25个对数发生比log( (1-p)/p) 的标准差为半径进行1∶1的最近邻匹配;2.此处以内核为基础的kernel匹配中使用默认的核函数与带宽,不加其他参数;3.使用默认的核函数与带宽,并用自助法(bootstrap)以得到自助标准误。
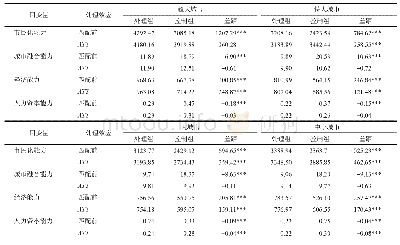
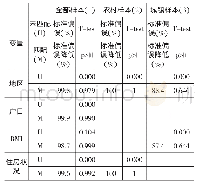
考虑到样本可能由于“自选择偏差”而引起内生性问题,为了得到更稳健的回归结果:即非正规就业对居民工作满意度的影响作用是否具有一致,稳定的效果,本文分别对全样本、分性别、分受教育年限样本,使用Rosembaum和Rubin(1985)提出的倾向得分匹配法(PSM)[35]重新估计非正规就业与居民工作满意度之间的关系。倾向得分匹配的思想假定:如果从事正规就业和非正规就业两种群体的差异能够被一组共同影响的因素(协变量X,如年龄、户籍、政治面貌等)完美解释,那么我们就可以用这些共同的因素进行分层匹配,使得每一层内由两种群体:正规就业者和非正规就业者,两者唯一的不同在于他们是否从事非正规就业,然后考察这两种群体的工作满意度差异。我们将从事非正规就业者视为处理组,将正规就业者视为控制组,在可观测特征条件下,用倾向得分把是否从事非正规就业视为一种概率,以此概率作为分层匹配的基础,可以得到较好的ATT(处理组效应)。利用Stata软件进行倾向得分匹配时,需要检验从事非正规就业和正规就业两种群体之间的其他控制变量(协变量)间平衡性,平衡性检验结果显示,匹配前从事非正规就业和正规就业的两组群体在个人特征变量方面存在显著差异,但匹配后的大部分变量的偏误比例都将至6%以下,除了周工作时间和工作环境的偏误比例处于6%~9%之间,但这些变量的偏误比例均在75%以上。T检验的概率值显示,以上匹配变量均不能在10%的显著性水平下拒绝匹配后处理组(非正规就业者)与控制组(正规就业者)无显著差异的原假设,即匹配结果通过了平衡性检验。本文采取卡尺内最近邻匹配、核匹配、局部线性回归匹配三种方法进行检验,这几种方法本质上相同的,这里采用多种方法是为确保检验结果更为可靠稳健,若通过不同方法得到的ATT结果在方向与显著性上都相同,则表明结果相对可靠。具体全样本及分样本倾向得分匹配的ATT处理效应见表5。
| 图表编号 | XD0015088900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.11.25 |
| 作者 | 刘翠花、丁述磊 |
| 绘制单位 | 东北财经大学经济学院、东北财经大学经济学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}