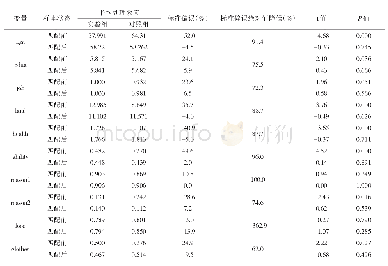
《表5 倾向得分匹配的样本均衡性检验》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:限于篇幅,其余控制变量未一一列举。匹配前Ps R2、LR chi2、标准偏差均值和中位数分别为0.084、1611.37、17.4和13.0;匹配后相应数值为0.002、20.23、1.9和2.1,匹配效果较好。*、**、***分别表示在10%、5%、1%水平上显著。
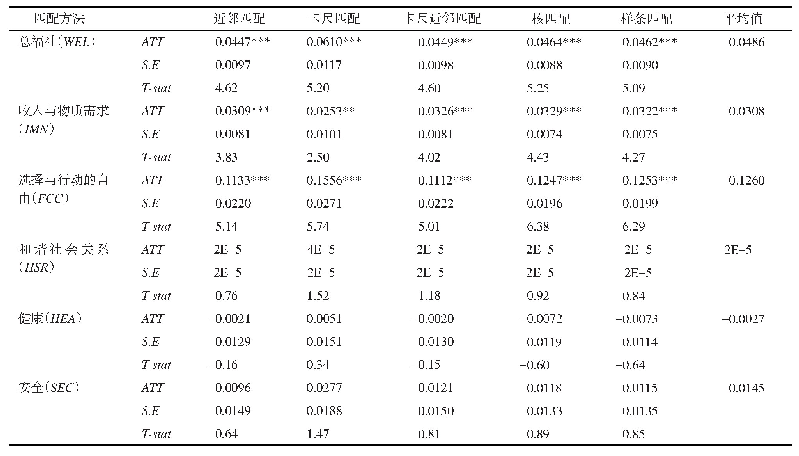
为了估计互联网对大学毕业生就业工资影响的净效应,本文采用倾向得分匹配方法进行估计,以最大程度上控制可能存在的内生性和选择性偏差问题。倾向得分匹配分析在具体应用的过程中,常见的匹配方法有三类,分别是最近邻匹配、半径匹配和核匹配。本文借鉴这三类方法进行验证。倾向得分匹配需要对样本进行均衡性检验,均衡性检验如表5所示,从中可以看出,在匹配后的绝大多数变量的标准偏差均小于10%,同时大多数变量在样本匹配前的P值非常显著,匹配后则多数变量不显著,这也表明样本选择偏差在很大程度上得以消除。此外,整体均衡性检验同样显示样本的均衡性较好,通过倾向得分匹配方法纠正样本的选择性偏差具有可靠性。
| 图表编号 | XD0063180500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.02.01 |
| 作者 | 赵建国、周德水 |
| 绘制单位 | 东北财经大学、东北财经大学公共管理学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}