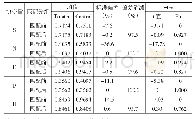
《表3 倾向得分匹配的平衡性检验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《管理提升了企业劳动生产率吗——来自中国企业——劳动力匹配调查的经验证据》
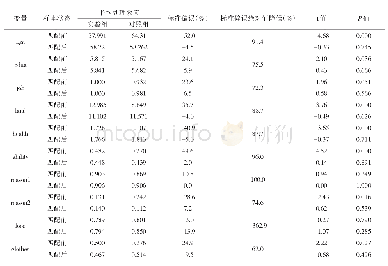
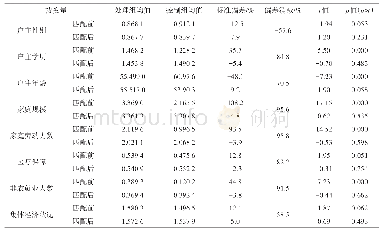
注:根据2015年企业是否属于“高管理效率”分组进行1比1的k近邻匹配。*、**和***分别表示在1%、5%和10%水平上显著。
具体而言,我们首先根据受访企业2015年管理效率得分是否大于或等于中位值,将全部企业样本划分为“高管理效率”(M_high)、“低管理效率”(M_low)两组。在此基础上,分别选择人均固定资产净值、劳动力人数和研发人员占比作为“高管理效率”企业与“低管理效率”企业的匹配变量,对全部受访企业样本以劳动生产率(人均工业增加值)作为产出变量进行1:1的k近邻匹配。在此基础上,剔除找不到匹配对象的企业,最终分别得到300对(共600家)企业作为倾向得分匹配回归的子样本。表2报告了配对分组变量和企业维度匹配变量的统计结果,表3则进一步报告了k近邻匹配(n=1)估计的平衡性检验结果。从中可以看到,采用PSM配对之后,“高管理效率”分组与“低管理效率”分组在企业规模、研发人员占比等特征上的标准误绝对值减少了82.5%~90.1%。这表明,采用配对样本回归,可在一定程度上有效剔除企业规模、要素禀赋状况等特征的组间差异,从而规避选择性偏误对管理效率影响效应估计值的潜在干扰。
| 图表编号 | XD0020989300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.02.15 |
| 作者 | 程虹 |
| 绘制单位 | 武汉大学质量发展战略研究院、宏观质量管理湖北省协同创新中心 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}