《表3 倾向得分匹配前后解释变量平衡性检验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
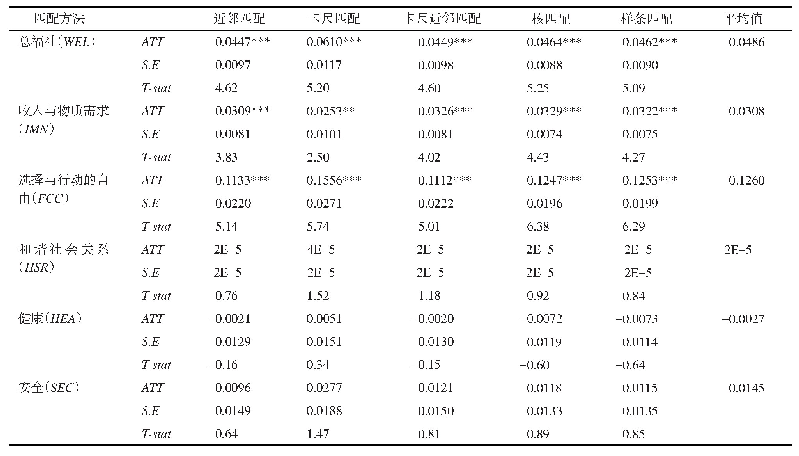
图5显示了匹配前和一对一匹配后参与三产融合组农户和未参与三产融合组农户的倾向值密度曲线。匹配前两组农户的倾向值在主体部分有重叠,这为基于倾向值的匹配提供了共同支撑区域。多种匹配方法得到的结果是类似的,限于篇幅,图中展示了一对一匹配后两组农户倾向值的密度曲线。从图形来看,匹配后未参与三产融合组的密度曲线匹配前在0.25以下的高峰变得平坦了许多,不仅与参与三产融合组有较大范围的重叠,且呈现出与参与三产融合组相似的升降趋势,两组之间特征差异减小。从数据来看,表3显示了协变量平衡性检验结果。样本匹配前,解释变量的标准化偏差为31.6%,样本匹配后,这一偏差降低到了1.4%~4.2%。匹配前后解释变量总体偏误显著降低且小于平衡性检验规定的20%红线标准(王慧玲和孔荣,2019);[23]伪R2方从0.161降低到了0.001~0.007;LR统计量从158.10下降到了0.65~5.67。此外,由表4可知,一对一匹配后损失样本14个,保留了700个有效样本。由此可见,本研究中PSM匹配效果良好。
| 图表编号 | XD00222844700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.25 |
| 作者 | 李姣媛、覃诚、方向明 |
| 绘制单位 | 浙江工商大学金融学院、中国农业大学经济管理学院、中国农业大学经济管理学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}