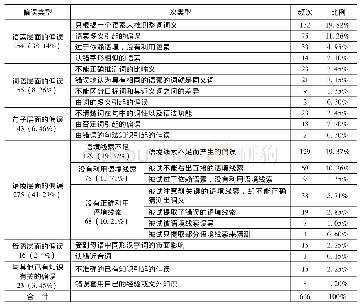
《表1 被试在阅读中推测词义的偏误类型》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:因四舍五入,次类型的比例实际加和略小于100%。
通过上文的分析,可以看出汉语学习者在阅读中推测生词词义的偏误情况错综复杂。作者统计了所收集到的实例,总计发现偏误666例(表1)。其中语境层面的偏误最多,有275例,占比高达41.29%。语素层面的偏误254例,占比38.14%,词语层面的偏误55例(8.26%),句子层面的偏误43例(6.46%),与其他已有知识有关的偏误23例(3.45%),母语层面的偏误16例(2.4%)。在偏误次类型方面,偏误频次超过总频次10%的包括:只根据一个语素来推测整词词义132例(19.82%),语境线索不足而产生的偏误129例(19.37%),语素多义引起的偏误75例(11.26%),以及被试不能看出直接的语境线索69例(10.36%)。可以看出,偏误主要出现在语境层面和语素层面。
| 图表编号 | XD00148980400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.20 |
| 作者 | 汤明 |
| 绘制单位 | 华侨大学华文学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}