《表1 实验字对信息:汉字亚词汇部件语音加工的P200效应》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
所有实验用字选自常用的4574个字(北京语言学院语言教学研究所,1986)。关键材料为部件发音和部件不发音高频字对。为了方便描述,每一字对中的第一个字称为启动字,第二个字称为目标字。所有字对均为形似音异字,启动字和目标字共享一个部件。部件发音和不发音字对各有35对,每对字对之间没有语义相关。实验中还包括24对形似音异但语义相关的字对(如,“瞅–瞧”)作为填充字对。每种条件下目标和启动字的笔画和字频都进行严格匹配,部件发音和不发音两种条件下材料的笔画和字频也完全匹配。所有目标字的部件家族大小都没有差异,都在2~15个之间,属于研究文献中界定的小家族(毕鸿燕等,2006)。实验材料中可发音和不可发音字对目标字的一致性也严格匹配(0.25与0.26,p=0.832)。每个被试接受总共94对随机呈现的字对,见表1。
| 图表编号 | XD00146841800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.20 |
| 作者 | 孔令跃、张豹 |
| 绘制单位 | 北京大学对外汉语教育学院、广州大学教育学院心理学系 |
| 更多格式 | 高清、无水印(增值服务) |

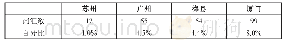



{kind=link}